Etched AI: Future of Transformers ?
Written by:- Omkar Bhope

On 25 June 2024, Etched AI announced their Sohu chip, the world’s first Application Specific Integrated Circuit built specifically for Transformers. The foundation of Etched AI is based on the bet made in the world of AI, that transformers are the upcoming future and are soon going to take over the world. But is this bet grounded in reality? In this piece, I will undertake a comprehensive analysis of existing systems and put the Sohu chip through rigorous scrutiny, evaluating its performance across key metrics to determine its potential to disrupt the market.
Company’s Vision and Mission:
Etched AI, led by CEO Gavin Uberti, is on a mission to revolutionize AI hardware by addressing one of the industry's greatest challenges: creating purpose-built chips for large language models (LLMs) that surpass existing GPUs in performance, efficiency, and scalability. Under Uberti’s visionary leadership, Etched is redefining the future of AI hardware to enable transformative AI experiences at a scale never seen before.
Gavin Uberti, often likened to Sam Altman for his impact-driven approach, brings a unique blend of expertise and passion to the table. A Harvard dropout with a background in mathematics and computer science, Uberti honed his skills at OctoML and Xnor.ai, contributing to cutting-edge advancements in deep learning compilers and efficient neural network implementations. Alongside him are cofounders Robert Wachen and Chris Zhu, both recipients of the prestigious Thiel Fellowship, further cementing the team’s reputation as a powerhouse of innovation.
Supporting the founders is a team of industry stalwarts, including Mark Ross, former CTO at Cypress Semiconductor; Ajat Hukkoo, with decades of experience at Intel and Broadcom; and Saptadeep Pal, Chief Architect and cofounder of Auradine. This collective of seasoned professionals ensures that Etched’s ambitious vision is in the most capable hands.
The Sohu chip, Etched’s flagship innovation, exemplifies the company’s mission to deliver hardware optimized specifically for transformer models. By unlocking unprecedented speed and efficiency, the Sohu chip aims to make once-impossible AI applications—like ultra-fast inference for real-time decision-making and AI-generated creative breakthroughs—a reality. Backed by a $120 million funding round, Etched is well-positioned to challenge industry giants like NVIDIA and lead the AI hardware revolution toward a future defined by superintelligence.
What is ASIC?
ASICs are specialized processors that are made for one purpose: running specific computational jobs at the highest efficiency possible. In contrast to general-purpose processors, such as CPUs or GPUs, ASICs are designed with a laser-sharp focus on the performance of narrow tasks with unparalleled speed, energy efficiency, and precision. Their tailored architecture makes them indispensable for handling the immense computational loads of modern AI models, especially transformative technologies like neural networks and transformers.
What makes ASICs truly revolutionary is their ability to deliver peak performance while consuming significantly less power. What it means for developers is faster training of models, efficient model deployments, and decreased operational costs—all the while pushing the boundaries of what AI can achieve, from natural language processing to real-time decisions in industries like healthcare or automotive.
With increasing demands for AI, the need for specialized solutions like ASICs is becoming more evident. ASICs are already changing industries, but the Sohu chip from Etched AI is taking it further. Purpose-built for transformer-based models, the Sohu chip optimizes speed and scalability, setting new standards in AI hardware. With this chip leading the charge for the AI hardware revolution, it is making applications that were once the realm of science fiction an everyday reality.
Does the Industry need transformers?
In the industry, almost 82% of companies are either currently using AI or considering its implementation. However, each company has its own use case and their specific needs. There are many sophisticated algorithms built that are fast, reliable, and easily suffice the needs of customers making them the obvious choice of implementation for the companies. Here’s a list of companies using different AI models:
In today’s fast-evolving tech landscape, nearly 82% of companies are either using AI or exploring its implementation, the technology has become a cornerstone of innovation across industries. However, each business has unique needs and challenges, requiring tailored AI solutions to deliver real value. Sophisticated algorithms, celebrated for their speed, reliability, and scalability, have become the go-to choice for companies aiming to meet and exceed customer expectations. From streamlining operations to enhancing user experiences, businesses are leveraging diverse AI models to address specific use cases, driving competitive advantage and transformative progress. Here’s a list of companies and the AI models they are using:
| Popular Models | Used by Companies |
| Convolutional Neural Networks (CNNs)- Examples: AlexNet, VGG, ResNet | - Google: Image search and classification- Facebook: Image recognition and tagging |
| Recurrent Neural Networks (RNNs)- Examples: Vanilla RNN, Bidirectional RNNs | - Apple: Siri's speech recognition- Google: Google Translate |
| Long Short-Term Memory Networks (LSTMs) | - Amazon: Alexa's voice processing- Netflix: Content recommendation systems |
| Gated Recurrent Units (GRUs) | - Spotify: Music recommendation systems- Alibaba: E-commerce product recommendations |
| Variational Autoencoders (VAEs) | - Adobe: Image editing and synthesis tools- NVIDIA: Research in image generation |
| Generative Adversarial Networks (GANs)- Examples: StyleGAN, CycleGAN | - NVIDIA: Graphics and image generation- DeepMind: Research in data augmentation |
| Support Vector Machines (SVMs) | - AT&T: Fraud detection- Bioinformatics Companies: Gene expression classification |
| Decision Trees and Random Forests | - Banking Sector: Credit scoring and risk assessment- Healthcare: Disease prediction models |
| K-Means Clustering | - Marketing Firms: Customer segmentation- Telecommunications: Network optimization |
| Principal Component Analysis (PCA) | - Finance: Portfolio management- Genetics Research: Data dimensionality reduction |
| Hidden Markov Models (HMMs) | - Speech Recognition Systems: Various companies- Bioinformatics: Sequence analysis |
| Markov Random Fields (MRFs) | - Image Processing Firms: Image restoration- Natural Language Processing: Contextual data modeling |
| Monte Carlo Simulations | - Financial Institutions: Risk assessment- Energy Sector: Resource allocation planning |
| Genetic Algorithms (GAs) | - Automotive Industry: Design optimization- Telecommunications: Network design |
| Particle Swarm Optimization (PSO) | - Robotics: Path planning- Engineering Firms: Structural design optimization |
| Reservoir Computing | - Time-Series Prediction: Various research applications- Signal Processing: Real-time data analysis |
If we take a closer look at the above list, all these models are non-transformer-based and highly accepted in the industry. So, why Transformers? Even though there are many sectors where the usage of large transformer models might be unnecessary, the continuous evolution in the field of Transformers such as the exploration of attention mechanisms for faster inference, adaption of techniques like LoRA, Quantization, pruning, speculative decoding, etc to provide better and faster models are making Transformers an obvious choice for many if not all use cases.
Here’s a list of all the companies that are slowly switching from Traditional AI models to Transformers:
| Company | Traditional Models Used | Transformer-Based Models Adopted |
| - Recurrent Neural Networks (RNNs)- CNNs for Vision Tasks | - BERT (Search ranking and NLP tasks)- PaLM (Large-scale NLP)- ViT (Vision Transformer for image classification) | |
| OpenAI | - LSTMs for early language models | - GPT Series (e.g., GPT-3, GPT-4 for conversational AI and general NLP)- DALL-E (Image generation from text)- CLIP (Multi-modal tasks combining vision and text) |
| Microsoft | - RNNs for NLP | - Turing-NLG (NLP tasks)- OpenAI GPT integration (e.g., Copilot in Microsoft 365)- BERT variants (Search in Bing) |
| Meta (Facebook) | - CNNs for image recognition | - LLaMA (Large Language Model Meta AI) for generative NLP- DETR (DEtection TRansformer for object detection) |
| Amazon | - Collaborative filtering for recommendations- RNNs for Alexa | - AlexaTM (Transformer Model) for language understanding in Alexa- Vision Transformer (ViT) for product recommendations |
| IBM | - Rule-based systems for NLP | - Watson NLP models based on BERT architecture- Project Debater AI using transformers for argument generation |
| Salesforce | - Traditional ML for analytics | - Einstein GPT (Generative AI for CRM)- CTRL (Conditional Transformer for Language tasks) |
| Adobe | - GANs for image generation | - Firefly (Generative AI using transformers for creative applications)- ViT for enhancing visual creativity tools |
| NVIDIA | - CNNs for image processing | - Megatron (Large transformer model for research)- StyleGAN augmented with transformer components for synthesis tasks |
| Apple | - RNNs for Siri's speech recognition | - Exploring TransformerXL and BERT variants for Siri’s enhanced understanding- ViT for internal computer vision research |
In recent years, there has been an unprecedented Demand for transformer based models in the market. Before ChatGPT, the market for transformer inference was ~$50M, and now it’s billions. All big tech companies use transformer models (OpenAI, Google, Amazon, Microsoft, Facebook, etc.).
Also, AI model designs have become much more stable. In the past, top AI models often saw big, disruptive design changes. But since GPT-2 came out, the leading models have stuck to a design called the "transformer paradigm." This approach is now used in major models like OpenAI's GPT family, Google's PaLM, Facebook's LLaMa, and even Tesla's self-driving systems.
Transformers are powerful, useful, and profitable enough to dominate every major AI compute market before alternatives are ready. Transformers power every large AI product: from agents to search to chat. Although these models are used for very different tasks—like writing text, generating images, or helping cars drive—they share a lot of the same underlying structure. Small tweaks, like using SwiGLU activations or RoPE encodings, are what make them unique for specific jobs.
What's surprising is how consistent this core design has stayed over the years. Even with a five-year gap between GPT-2 and LLaMa-3, the basic architecture hasn’t really changed. Instead, improvements have come from scaling up: using bigger datasets, more computing power, and more complex models to achieve better results.
Need for more computation:
The global transformers market size is calculated at USD 63.13 billion in 2024 and is predicted to grow only further. According to “Sam Altman” the two primary challenges in the advancement of transformer-based AI models: are computational capacity and data availability. Training large language models, such as OpenAI's GPT-4, demands substantial computational resources. Altman has noted that a shortage of computing power has delayed the release of some of OpenAI's products. While we can’t resolve the data availability issue, Sohu’s extensive computational capabilities can play a pivotal role in the inference of future GPT models.
Meta used 50,000x more computing to train Llama (400B parameters 2024 SoTA) than OpenAI used on GPT-2 (1.5B parameters 2019 SoTA). Looking at the resource utilization for training, we can easily estimate that the computational resources required for inference will be equally higher.
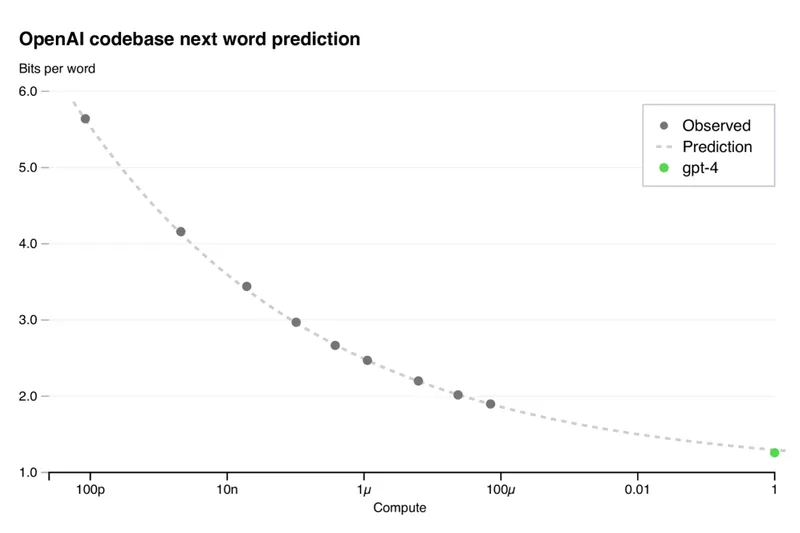
AI companies like Google, OpenAI, Microsoft, Anthropic, Amazon, etc. are spending more than $100 billion over the next few years to keep scaling. Amazon Web Services (AWS) is investing over $500 million in three nuclear energy projects located in Washington state, Virginia, and Pennsylvania. These investments aim to meet the escalating power demands of AWS's AI programs, including those utilizing Trainium chips. Similarly, other tech giants like Google and Microsoft are also exploring nuclear energy to power their data centers.
While these energy sources will provide carbon-free electricity for the data centers, they are still hazardous to nature increasing the amount of radioactive waste and additional cost for handling that waste. Sohu chip can be proven as a transformative alternative for LLM inference given its exceptional capabilities. Sohu delivers a near-impossible throughput of 500,000 token/s for the LLaMA 70B model, which surpasses every available computational system in the market. From this, we can infer that Sohu will perform equally exceptionally with other transformer models making it an obvious choice for future LLM inferencing because of its cost-effectiveness and energy-efficient nature.
World leaders like Dario Amodei, and Sam Altman quote “I think we can scale to the $100B range, we’re going to get there in a few years", "Scale is really good. When we have built a Dyson Sphere around the sun, we can entertain the discussion that we should stop scaling, but not before then". These quotes give a glimpse of the future with LLMs far bigger and better than the current state-of-the-art LLMs. However, Scaling the next 1,000x will be very expensive. The next-generation data centers will cost more than the GDP of a small nation. At the current pace, our hardware, power grids, and pocketbooks can’t keep up. Currently, the world's largest LLM is GPT-4 consisting of 1.75 Trillion parameters. The Sohu’s stage A chip is Expansible to 100 Trillion parameter models making it ready for future LLMs.
Who are the existing market leaders ?
Many companies are building powerful GPUs and TPUs to handle the huge workloads. To name a few:
- NVIDIA's GPUs:
- H100 Tensor Core GPU: Built on the Hopper architecture, the H100 utilizes TSMC's N4 process, comprising 80 billion transistors and up to 144 streaming multiprocessors. It supports HBM3 memory with bandwidth up to 3 TB/s, enhancing performance for AI and high-performance computing (HPC) workloads.
- B200 GPU: As part of the Blackwell architecture, the B200 is designed to succeed the H100, offering up to twice the performance in certain AI benchmarks. However, reports indicate potential overheating issues, leading to design adjustments and possible delivery delays.
- Google's TPUs:
- TPU v5p: Google's TPU v5p has demonstrated significant improvements in AI training tasks, surpassing NVIDIA's H100 in specific benchmarks.
- Trillium Chip: Introduced in May 2024, the Trillium chip enhances AI data center performance nearly fivefold compared to its predecessor, achieving 4.7 times better computing performance and 67% greater energy efficiency.
- Amazon's Trainium:
- Trainium2: AWS's second-generation AI chip, Trainium2, is designed to compete with NVIDIA's offerings, with plans to integrate it into supercomputers like the "Ultracluster." Companies such as Anthropic intend to utilize Trainium2 for training AI models.
- AMD's Accelerators:
- MI300X: AMD's MI300X, based on the CDNA 3 architecture, features a substantial cache hierarchy and supports HBM3 memory. Low-level benchmarks indicate strong performance, with significant improvements over its predecessor.
Why GPU’s are not the future of AI?
Historically, GPUs have enjoyed rapid advancements in compute density, often doubling performance every two years in line with Moore's Law. However, recent data reveals that this exponential growth has tapered:
- 2018-2021: GPUs saw compute density improvements averaging 20-30% annually, driven by architectural innovations and advanced manufacturing processes (7nm to 5nm nodes).
- 2022-2024: The annual improvements have decelerated to around 5-15%, indicating that manufacturers are encountering physical and economic barriers in further scaling compute density.
Progress in GPU performance has stagnated, particularly when measured by compute density—TFLOPS per square millimeter of chip area. GPUs haven't fundamentally improved in efficiency; instead, they’ve increased in physical size to deliver more computing power. This has led to a plateau in compute density, a critical metric for evaluating true performance progress.
- NVIDIA H100 vs. TPUv5: Launched in 2023, NVIDIA's flagship H100 GPU offers approximately 60 TFLOPS of compute power. In comparison, Google's TPUv5, introduced around the same time, delivers roughly 65 TFLOPS. Notably, their compute densities—TFLOPS per square millimeter—are nearly identical ~25 TFLOPS/mm², indicating that both architectures have reached similar efficiency levels despite their differing designs.
- AMD MI300X, NVIDIA H200, Intel Gaudi 3: These next-generation GPUs, released between 2023 and 2024, cluster closely in terms of compute density, each achieving around 25 TFLOPS/mm². This clustering signifies that significant leaps in compute density are rare, with each new generation only offering marginal improvements (approximately 5-10%) over its predecessor.
- Projected NVIDIA B200 (2025): Forecasts suggest that the upcoming NVIDIA B200 will only achieve a compute density of about 27 TFLOPS/mm², representing a mere 8% improvement over the H200. This projection underscores the industry's slow trajectory in enhancing compute density.
| Feature | NVIDIA H100 | Google TPU v5p | AMD MI300X | NVIDIA H200 | Intel Gaudi 3 |
| Architecture | Hopper | Proprietary Tensor Processor | CDNA 3 | Enhanced Hopper | Proprietary AI Accelerator |
| Memory | 80 GB HBM3 | Proprietary | 192 GB HBM3 | 141 GB HBM3e | 128 GB HBM2e |
| FP8 Performance | 1,979 TFLOPS (3,958 w/ sparsity) | Estimated ~2,000+ TFLOPS | 2,573 TFLOPS | 2,200 TFLOPS (4,400 w/ sparsity) | 1,835 TFLOPS |
| BF16 Performance | 989.4 TFLOPS | Estimated ~2,000+ TFLOPS | 1,835 TFLOPS | 1,100 TFLOPS (2,200 w/ sparsity) | 1,835 TFLOPS |
| INT8 Performance | 3,958 TOPS | Estimated ~4,000+ TOPS | 3,670 TOPS | 4,400 TOPS | 3,670 TOPS |
| Memory Bandwidth | 3 TB/s | Estimated ~2.5 TB/s | 5.2 TB/s | 4.5 TB/s | 2.5 TB/s |
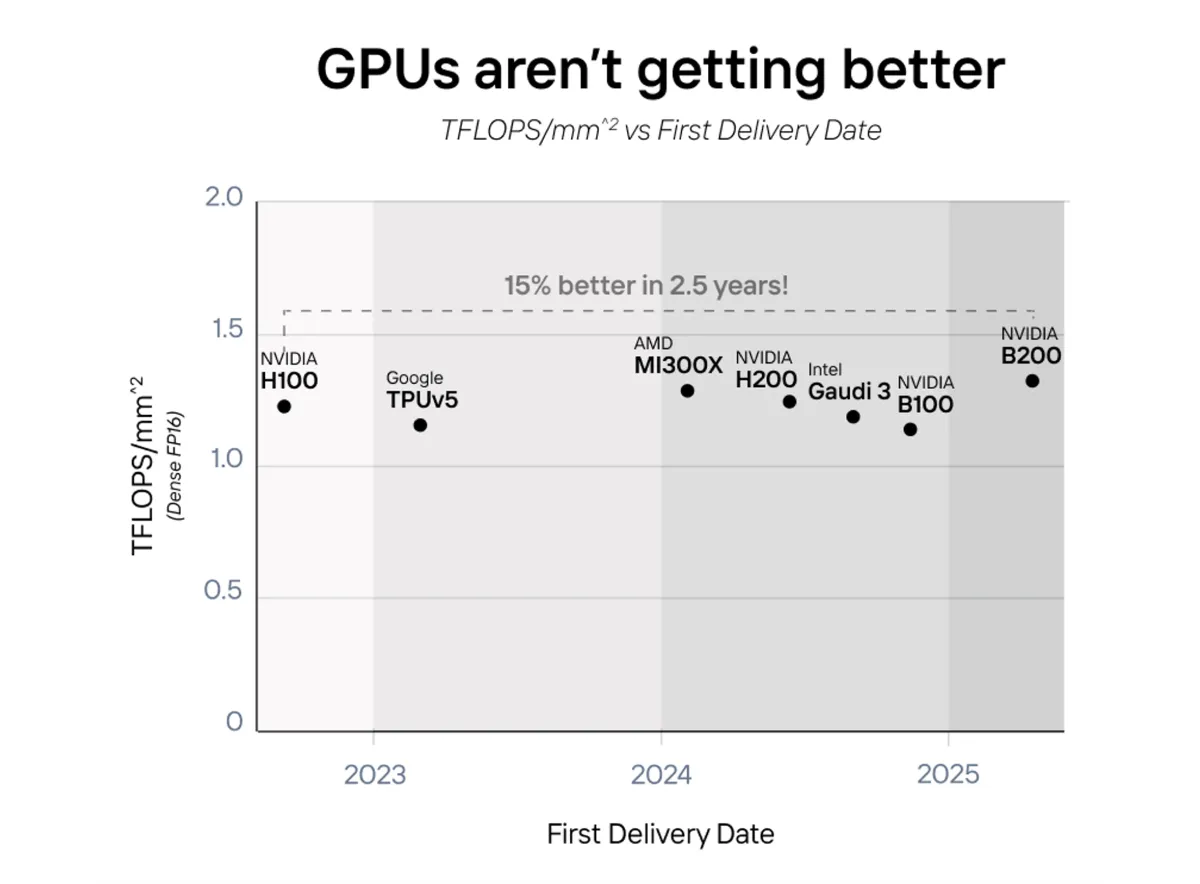
Larger GPU chips have become increasingly expensive to produce, with die sizes growing from 500 mm² to 600 mm², driving costs up by approximately 20% due to higher defect rates and reduced yields. This rising cost is unsustainable as demand for cost-effective AI inferencing grows. At the same time, stagnant compute density has led to larger chips consuming more power per compute task, with NVIDIA reporting a 10% increase in power consumption per TFLOPS over the past two years, further escalating operational costs and environmental impact. While advancements like 3D stacking and advanced packaging have offered incremental improvements, they have not resolved the underlying stagnation in compute density, highlighting the physical and economic limitations of current GPU architectures.
This stagnation in GPU compute density underlines a critical juncture in the evolution of AI inferencing hardware. As GPUs reach their physical and economic limits, the industry must pivot towards specialized solutions like ASICs, TPUs, and other custom accelerators that offer superior efficiency and scalability. Embracing these specialized technologies will be essential to meet the burgeoning demands of next-generation AI applications, ensuring sustainable growth and innovation in the field.
What are the existing specialized chips in the market ?
Graphcore's IPUs:
- Intelligence Processing Units (IPUs): Graphcore's IPUs are designed for parallel processing of AI workloads, offering high performance across diverse models.
SambaNova's SN Series:
- SN Series: SambaNova provides integrated hardware and software systems optimized for AI workloads, delivering high performance for various applications.
Cerebras's CS-2:
- Wafer-Scale Engine (WSE): The CS-2 is powered by the Wafer-Scale Engine (WSE), a groundbreaking AI accelerator with 850,000 cores on a single wafer, designed for extreme scalability and efficiency in training large-scale AI models. Its unique architecture delivers unparalleled performance for high-complexity workloads in research and enterprise AI.
Groq's GroqNode:
- GroqNode is a deterministic AI accelerator designed to optimize inference workloads with high performance and low latency. Its architecture is ideal for real-time applications requiring consistent processing speeds.
Tenstorrent's Grayskull:
- Grayskull is a scalable AI processor that emphasizes flexibility and performance across diverse AI workloads. It is well-suited for training and inference tasks in distributed computing environments.
D-Matrix's Corsair:
- Corsair is a specialized chip optimized for AI inference, designed to handle large-scale user requests efficiently. It focuses on energy efficiency and scalability, making it ideal for cloud and edge AI applications.
Cambricon's Siyuan:
- Siyuan: Cambricon develops AI chips tailored for various applications, offering flexibility across different models. However, their general-purpose nature might not achieve the same level of efficiency as specialized chips in transformer-specific tasks.
Intel's Gaudi:
- Gaudi 3: Launched in October 2024, Intel's Gaudi 3 accelerator targets AI workloads, offering competitive performance at a lower price point compared to NVIDIA's H100, aiming to provide a cost-effective alternative for AI training and inference.
Why is Sohu better ?
While existing AI chips excel in efficiency and AI acceleration, most are designed to cater to a broad range of AI architectures, lacking a dedicated focus on any specific use case. In contrast, Sohu sets itself apart by embedding the Transformer architecture directly into its ASIC design. This level of specialization makes it exceptionally fast and efficient for transformer-based models, such as large language models and generative AI applications.
Developing a custom chip is a monumental challenge, typically costing $50–100 million and taking years to transition from concept to production. The Etched AI team has demonstrated remarkable dedication and technical prowess in realizing Sohu, overcoming these barriers with precision and innovation.
Sohu's potential is further validated by the backing of industry luminaries such as Peter Thiel, Kevin Hartz, Mike Novogratz, David Siegel, Balaji Srinivasan, and Kyle Vogt. These individuals are not only influential founders and CTOs of AI-driven companies but also represent a significant pool of potential clients for the Sohu chip. Their support underscores the transformative promise of Sohu in reshaping AI hardware for the future.
Sohu supports only transformer inference for all of today's models (Google, Meta, Microsoft, OpenAI, Anthropic, etc.) and can adapt to tweaks in future models. Since Sohu runs just one algorithm, it eliminates the need for the programmability that GPUs require to support a broad range of architectures. This specialization allows Sohu to dedicate far more transistors to matrix math operations. This design enables Sohu to achieve over 90% FLOPS utilization (compared to ~30% on a with TRT-LLM).
For example, NVIDIA’s H100 GPU has 80 billion transistors, but only 2.7 billion transistors i.e 3.3% of them are allocated to matrix multiplication. This is because the majority of the chip's area is used for programmability to support diverse AI workloads like CNNs, LSTMs, and other models. In contrast, Sohu’s design focuses solely on transformers, allowing it to allocate a much larger percentage of its transistors to compute operations like FP16/BF16/FP8 multiply-add circuits, which are critical for transformer performance.
Software development challenges:
Developing software for AI hardware like GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) is no small feat. The challenge lies in managing diverse programming tools like CUDA and PyTorch while ensuring compatibility and efficiency. The main difficulty comes from the need for highly advanced compilers, which translate AI models into instructions that these processors can execute efficiently.
Take NVIDIA's CUDA platform as an example. Introduced in 2007, CUDA has become a cornerstone for accelerating GPU-powered applications, including AI tasks. However, this advantage comes with added intricacies. Developers must meticulously align CUDA versions, NVIDIA drivers, and AI frameworks like PyTorch to avoid compatibility issues. For instance, leveraging tools like torch.compile() in PyTorch 2.0 requires specific versions of CUDA and drivers, adding to the development overhead.
It’s not just NVIDIA that faces these challenges. Competitors like AMD, Intel, and AWS are also heavily invested in building robust AI hardware and software ecosystems. Despite substantial R&D investments—like AMD’s 9% increase in just one quarter—achieving seamless compatibility and high performance remains a persistent hurdle.
This is where Sohu’s approach stands out. By focusing exclusively on transformer models, Sohu avoids the need for broad-spectrum development. Instead, the company channels its resources toward creating specialized, flexible software tailored for Large Language Model (LLM) inferencing. This strategic specialization not only reduces complexity but also enhances efficiency and adaptability in transformer-focused workflows.
Most companies running open-source or proprietary models rely on transformer-specific inference libraries like TensorRT-LLM, vLLM, or HuggingFace’s TGI. While these libraries excel in tweaking hyperparameters, they lack flexibility for modifying underlying model code. However, given the structural similarity across transformer models—whether text, image, or video—hyperparameter adjustments are often sufficient for 95% of AI companies.
For the remaining 5%, particularly the largest AI labs, customization is essential. These labs employ dedicated engineering teams to hand-tune GPU kernels, extracting every ounce of performance by reverse-engineering components like low-latency registers and tensor core optimization.
Sohu disrupts this paradigm with Etched, its open-source software stack. Researchers no longer need to reverse-engineer GPU kernels. With Etched, they gain granular control over everything from drivers to kernels to the serving stack, enabling unprecedented levels of customization. This not only accelerates innovation but also positions Sohu as a pioneer in transformer-specific software solutions.
Conclusion:
In conclusion, after a comprehensive survey of all the existing technologies and the merits of Sohu over its competitors, I firmly believe that we are in a new era with Sohu stearing us towards the AI revolution. Etched AI’s bet on the transformer architecture might seem a bit risky, but in a world where transformers now dominate every major AI domain—from language to vision—Sohu isn’t just another chip; it’s the hardware revolution AI has been waiting for.
The convergence of AI models around transformers has made Sohu the most critical hardware project of the decade. By partnering with TSMC on their cutting-edge 4nm process, securing top-tier hardware supply chains, and attracting the brightest minds from leading AI chip projects, Etched AI is on track to deliver one of the fastest chip launches in history. Early customer commitments and the unprecedented demand for Sohu validate its transformative potential.
If you're ready to experience this transformation firsthand, the time is now. Apply for early access to the Sohu HDK and be part of the revolution that will redefine AI as we know it.
https://www.etched.com/